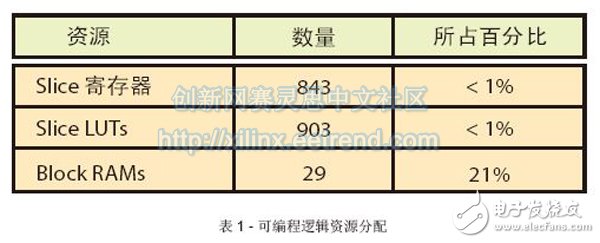
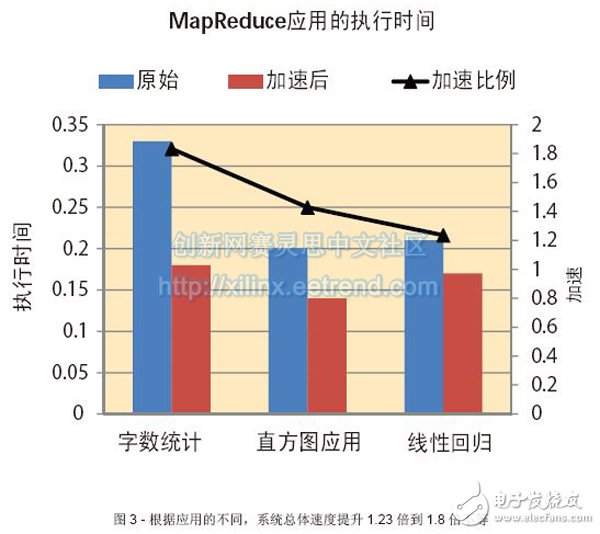
The novel reconfigurable hardware accelerator accelerates application processing based on the MapReduce programming framework. Emerging Web applications such as streaming video, social networking, and cloud computing require a warehouse-scale data center that can accommodate thousands of servers. One of the main programming frameworks for processing large data sets in data centers and other computer clusters is the MapReduce framework [1]. MapReduce is a programming model that uses a large number of nodes to process large data sets. The user is responsible for setting the "Map" and "Reduce" functions, and then assigning tasks to the processor by the MapReduce scheduler. One of the main advantages of the MapReduce framework is that it can be hosted in multiple heterogeneous clusters of different types of processors. Most data centers are using high-performance general-purpose devices such as Intel Xeon, AMD Opteron, and IBM Power processors. However, these processors consume a lot of power even when the applications are not high computationally intensive and high I/O intensive. In order to reduce power consumption in the data center, microservers have recently received much attention as an alternative platform. Such low-cost servers typically use low-power processors used in embedded systems, such as ARM® processors. Microservers are primarily for lightweight or parallel applications, and the most effective way to handle such applications is to use a single server with sufficient I/O between nodes instead of a high-performance processor. Microserver solutions have many advantages, such as reduced acquisition costs, reduced footprint, and reduced power consumption for specific application types. In the past few years, several vendors such as SeaMicro and Calxeda have developed microservers based on embedded processors. However, the MapReduce framework takes up multiple resources of the embedded processor, which reduces the overall performance of cloud computing applications running on these platforms. To overcome this problem, our team has developed a hardware acceleration unit for the MapReduce framework that can be efficiently integrated with ARM IP cores on a fully programmable platform. To develop and evaluate the proposed solution, we chose the Xilinx Zynq®-7000 All Programmable SoC with integrated dual-core Cortex-A9 processor on the development board. MapReduce Hardware Accelerator Unit As shown, we have integrated a hardware accelerator unit in a Zynq SoC equipped with a pair of ARM CortexTM-A9 IP cores. Each core has its own instruction and data cache, and each cache can communicate with peripherals using a shared interconnect network. The accelerator communicates with the processor through a high performance bus connected to the interconnect network. The processor gives the keys and values ​​that need to be updated to the MapReduce accelerator by accessing the accelerator's specific registers. After the Map task ends, the accelerator accumulates the values ​​of all the keys. The processor only needs to send the key to the accelerator and read the final value in the register to retrieve the final value of the key. In this way, the proposed architecture can speed up MapReduce processing by sending non-blocking transactions to key/value pairs that need to be updated. Programming Framework Figure 2 shows the MapReduce application programming framework using hardware accelerators. In the original code, the Map level emits key/value pairs, while the Reduce level searches for the key and consumes several CPU clock cycles to update (accumulate) the new value. In contrast to the MapReduce accelerator, the Map level only transmits key/value pairs, while the MapReduce accelerator combines all key/value pairs and updates related entries, eliminating the need for Reduce functionality. The Hash function speeds up the indexing process of the key, but if the two keys have the same hash value, it may cause a conflict. We chose Cuckoo Hashing as the best way to resolve Hash conflicts. Communication between the application layer running under Linux and the hardware accelerator is performed by using a memory map (mmap) system call. The mmap system call maps the specified kernel memory area to the user layer so that the user can read or write to it based on the attributes provided in the memory map process. We use the control unit to access updates to these registers and serialized key/value components. Key/value pairs are stored in memory locations that can be configured according to application requirements. The memory module contains keys, values, and partial digits that can be used as labels. These tags are used to indicate if the memory line is empty and valid. In order to speed up the indexing process of the key, the initial key can be converted to the address of the memory module by the hash module. In the current configuration, we designed a memory structure that can hold 2,000 key/value pairs. Each key can be up to 64 bits (8 characters long) and the value can be up to 32 bits long. The overall size of the memory structure is 2K x 104 bits. The first 64-bit stored key is used to compare whether we hit or miss using the Hash function; the next 8 bits are used to store the tag; the next 32 bits are used to store the value. In the current configuration, the maximum key value is 64 bits, and the hash function is used to map the key (64 bits) to the memory address (12 bits). Cuckoo Hashing The Cuckoo Hashing algorithm can be implemented using two tables, T1 and T2. TI and T2 correspond to a hash function, each of which is r. Each table uses a different hash function (h1 and h2, respectively) to create the addresses of T1 and T2. Each component x is stored in T1 or T2 after Hash function h1 or h2, respectively, ie, T1[h1(x)] or T2[h2(x)]. This method of searching is simple and straightforward. For each component x we ​​need to find, we only need to check the two possible positions in the T1 and T2 tables using the Hash functions h1 and h2, respectively. To insert component x, we need to check if T1[h1(x)] is empty. If it is empty, you can store component x in this location. If it is not empty, we replace the component y already existing in T1[h1(x)] with x. Then check if T2[h2(y)] is empty. If it is empty, we store component y in this location. If it is not empty, replace component z in T2[h2(y)] with y. Then we try to store z in T1[h1(z)], and so on, until we find an idle position. According to the original Cuckoo Hashing article [2], if you can't find a free location after a certain number of attempts, it is recommended to reprocess all the components in the table. In our current implementation of software, whenever the operation enters this loop, the software stops running and returns 0 to the function call. The function call may then initiate a re-hash process, or it may choose to add a specific key to the software memory structure as in the original code. We use Cuckoo Hashing for the MapReduce accelerator shown in Figure 1. We used two block RAMs to store entries for both T1 and T2 tables. These BRAMs store keys, values, and labels. Use 1 bit in the label field to indicate whether a particular column is valid. Use two Hash functions based on simple XOR functions to map keys to the address of the BRAM. Each time you need to access the BRAM address, you need to use the Hash table to create the address, and then according to the instructions of the two comparators to determine whether you can hit the BRAM (that is, the created key is the same as the key stored in the RAM, and the valid bit is 1) . The control unit can coordinate access to the memory. We implemented the control unit as a finite state machine (FSM) that can perform Cuckoo Hashing. Performance Evaluation We have implemented the proposed architecture in the Zynq SoC. Specifically, we mapped the Phoenix MapReduce framework to the embedded ARM IP core under Linux 3. Whenever the processor needs to update key/value pairs, they send information through a specific function call function. To evaluate the performance of the system, we used three applications provided by the Phoenix framework, which were modified to run with hardware accelerators. These three applications are word count, linear regression, and histogram. The proposed solution is configurable and can be fine-tuned to the needs of the application. To evaluate the performance of the Phoenix MapReduce framework application, we have configured a 4K memory unit for the accelerator (which can store 4,096 key/value pairs, each with a 2K storage capacity). Each key can be up to 8 bytes in size. Table 1 shows the programmable logic resources of the MapReduce accelerator. As you can see, the accelerator consists essentially of memory, while the control unit is used for finite state machines, and the Hash function only occupies a small portion of the device. Figure 3 compares the execution time of the original application with the MapReduce accelerator application. Both measurements are based on the Xilinx Zynq SoC design. In the word count application, the task of the Map in the original application is to identify the word and then submit it to the Reduce task. The Reduce task then collects all key/value pairs and accumulates the value of each key. In accelerator applications, Map's task is to identify words and then submit the data to the MapReduce accelerator unit via the high-performance AXI bus. The key/value pairs are stored in registers (each processor is different), and then the accelerator accumulates the value of each key by accessing the memory structure. The reason for shortening the execution time for processor offloading is that in the original code, the Reduce task must first load the key/value table and then search for the required key in the full table range. Then, after the completion of the accumulation of values, the Reduce task must store the keys back to memory. After using the MapReduce accelerator, we can release the processor from this task, thus reducing the overall execution time of the MapReduce application. Cuckoo Hashing (O(1)) allows the key search to be done in the accelerator, while the processor is unobstructed during the key/value pair update process. As shown in Figure 3, the overall speed of the system has increased by 1.23 times to 1.8 times. The specific acceleration depends on the characteristics of each application. In the case of complex mapping functions, the acceleration performance of the MapReduce accelerator is less obvious. In applications where the mapping function is simpler and the overall execution time is small, the acceleration performance is significant because there is a large amount of overall execution time available for communication between the Map and Reduce functions. So in this case, the MapReduce accelerator can provide very significant acceleration. In addition, the MapReduce Accelerator can create fewer new threads in the processor, reducing the number of environment switches and execution time. For example, in a word count application, the average number of environmental switches has been reduced from 88 to 60. The MapReduce framework can be widely used in programming frameworks for multicore SoC and cloud computing applications. For multi-core SoC platforms such as the Xilinx Zynq SoC and cloud computing applications based on the MapReduce framework, our proposed hardware accelerators can reduce overall execution time by speeding down the Reduce tasks for these applications. For more details on how to use the Zynq SoC platform to accelerate cloud computing, please contact the lead author, Dr. Christoforos Kachris, or visit. Neoprene Zipper Cable Sleeve,Neoprene Cable Management Sleeve,Zipper Sleeve Cable Wrap,Neoprene Wire Sleeve Shenzhen Huiyunhai Tech.Co., Ltd. , https://www.cablesleevefactory.com
The MapReduce Acceleration Unit is responsible for handling efficient implementations of Reduce tasks. Its main job is to combine intermediate key/value pairs from various processors and provide a quick way to insert new keys and update (cumulative) key/value pairs. We implement the MapReduce accelerator as a coprocessor, which can be used as an extension of a multi-core processor through a shared bus. Figure 1 is a block diagram of the accelerator in a multi-core SoC. 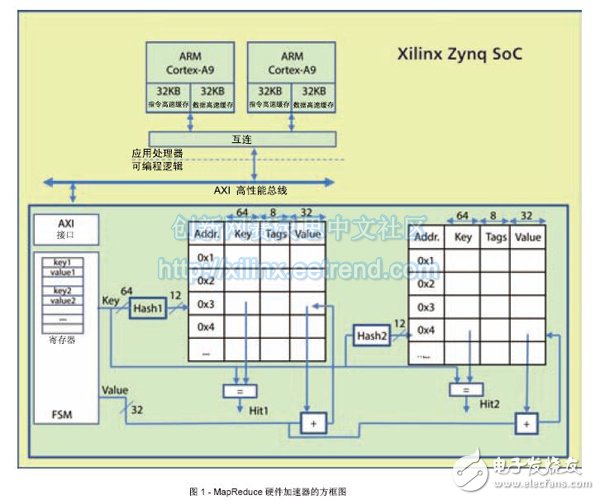

The Hash function speeds up the indexing process of the key, but it can also cause conflicts if two different keys have the same hash value. To solve this problem, we chose Cuckoo Hashing as the best way to resolve Hash conflicts. Cuckoo Hashing [2] uses two (rather than one) Hash functions. When a new entry is inserted, the entry is stored in the location of the first hash key. If the location is occupied, the old entry will be moved to its second hash address. This process loops back until it finds a free address. The algorithm provides a constant lookup time O(1) (the lookup only requires checking two locations in the hash table), while the insertion time depends on the size of the cache O(n). If the process should go into an infinite loop, the hash table is rebuilt.